![]()
![]()
Tilpassing av database til konkret DBHS.
Følgende tabelldefinisjoner gir et forslag til datatyper for MySQL:
CREATE TABLE Student
(
SNr CHAR(6),
Fornavn VARCHAR(40),
Etternavn VARCHAR(50),
Kjønn CHAR(1),
CONSTRAINT Student_PN PRIMARY KEY (SNr)
);
CREATE TABLE Ansatt
(
AnsNr INTEGER AUTO_INCREMENT,
Fornavn VARCHAR(40),
Etternavn VARCHAR(50),
Stilling VARCHAR(30),
CONSTRAINT Ansatt_PN PRIMARY KEY (AnsNr)
);
CREATE TABLE Kurs
(
Kurskode CHAR(5),
Kursnavn VARCHAR(50),
Studiepoeng SMALLINT,
CONSTRAINT Kurs_PN PRIMARY KEY (Kurskode)
);
CREATE TABLE Studium
(
SKode CHAR(3),
SNavn VARCHAR(50),
CONSTRAINT Studium_PN PRIMARY KEY (SKode)
);
CREATE TABLE StudiumOppbygging
(
SKode CHAR(3),
Kurskode CHAR(5),
SemesterNr SMALLINT,
CONSTRAINT StudiumOppbygging_PN PRIMARY KEY (SKode, Kurskode),
CONSTRAINT StudiumOppbygging_Studium_FN FOREIGN KEY (SKode)
REFERENCES Studium (SKode),
CONSTRAINT StudiumOppbygging_Kurs_FN FOREIGN KEY (Kurskode)
REFERENCES Kurs (Kurskode)
);
CREATE TABLE Kursavvikling
(
LøpeNr INTEGER AUTO_INCREMENT,
Kurskode CHAR(5),
AnsNr INTEGER,
Eksamensdato DATE,
CONSTRAINT Kursavvikling_PN PRIMARY KEY (LøpeNr),
CONSTRAINT Kursavvikling_Kurs_FN FOREIGN KEY (Kurskode)
REFERENCES Kurs (Kurskode),
CONSTRAINT Kursavvikling_Ansatt_FN FOREIGN KEY (AnsNr)
REFERENCES Ansatt (AnsNr)
);
CREATE TABLE Besvarelse
(
LøpeNr INTEGER,
SNr CHAR(6),
Karakter CHAR(1),
CONSTRAINT Besvarelse_PN PRIMARY KEY (LøpeNr,SNr),
CONSTRAINT Besvarelse_Kursavvikling_FN FOREIGN KEY (LøpeNr)
REFERENCES Kursavvikling (LøpeNr),
CONSTRAINT Besvarelse_Student_FN FOREIGN KEY (SNr)
REFERENCES Student (SNr)
);
Det er som regel hensiktsmessig å legge indekser på fremmednøklene:
CREATE INDEX StudentNavnIdx ON Student (Etternavn, Fornavn);
CREATE INDEX AnsattNavnIdx ON Ansatt (Etternavn, Fornavn);
CREATE INDEX KursnavnIdx ON Kurs (Kursnavn);
CREATE INDEX StudiumnavnIdx ON Studium (SNavn);
CREATE INDEX KursavviklingKursIdx ON Kursavvikling (Kurskode);
CREATE INDEX KursavviklingAnsattIdx ON Kursavvikling (AnsNr);
CREATE INDEX BesvarelseStudentIdx ON Besvarelse (SNr);
Hvis vi antar at DBHS innfører indekser på alle primærnøkler, har vi nå indekser på de fleste kolonner det er interessant å søke på? Heapfiler med balanserte flernivåindekser (B+-trær) er hensiktsmessig for samtlige tabeller i dette eksemplet.
Eksempel på mulig denormalisering: Legg kurskode og eventuelt studiepoeng inn i tabellen Besvarelse.
Antall diskaksesser.
Anta at hver rad krever 100 byte. For å unngå å fylle blokkene helt opp sier vi at hver blokk inneholder 30 rader. Med 5 millioner rader får vi ca. 167 000 blokker. Fordi vi organiserer folkeregisteret fysisk på personnummer må søk på etternavn skje sekvensielt (ettersom vi heller ikke har indekser). Dette gir i verste fall 167 000 diskaksesser, og i gjennomsnitt 83 500 diskaksesser.
Søk på personnummer kan i teorien gjøres med langt færre diskaksesser (selv uten indekser). Ettersom filen er fysisk sortert med hensyn på personnummer er det mulig å bruke binærsøk. Ved binærsøk halveres datamengden vi må søke i for hvert oppslag. 18 oppslag er dermed tilstrekkelig - fordi 218 = 262 144 > 167 00.
Indekser.
Hvis PersonNr er primærnøkkel får vi automatisk indeks på denne kolonnen. Hvilke andre kolonner vil oppretter indeks for avhenger av hvilke operasjoner som vi ofte vil utføre mot folkeregisteret. Hvis vi ofte søker / sorterer med hensyn på Etternavn bør denne kolonnen indekseres. Adresse vil nok også være en kandidat for indeksering. Det er også mulig å lage indekser på kombinasjoner av kolonner, for eksempel Etternavn og Fornavn. En slik indeks vil samtidig effektivisere søk i Etternavn alene.
CREATE INDEX NavnIdx ON Person(Etternavn);
CREATE INDEX AdresseIdx ON Person(Adresse);
Skisser av indekser.
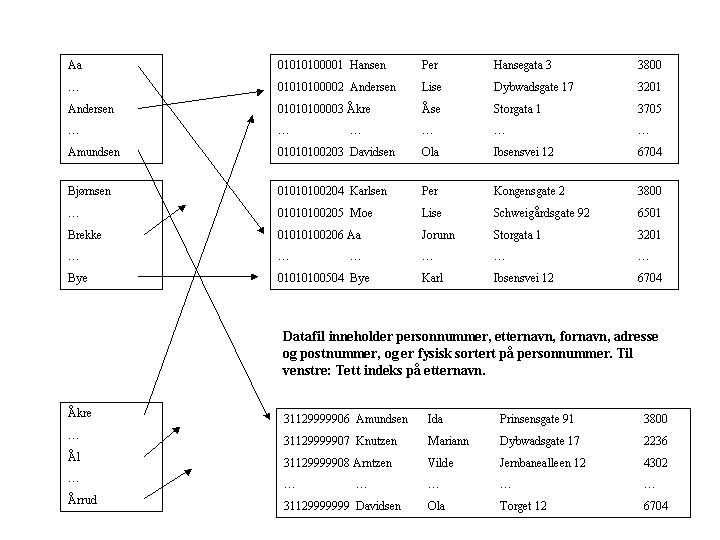
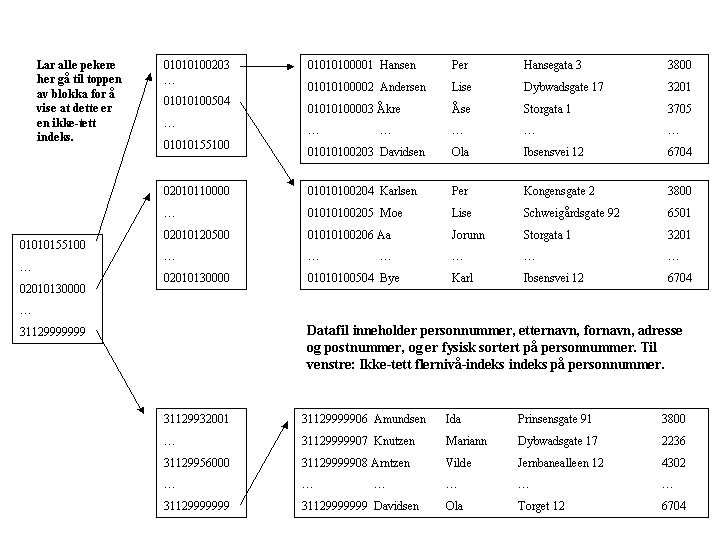
En tett indeks har én inngang for hver post i "datafilen", mens en ikke-tett indeks vil ha en inngang for hver blokk. Vi kan kun ha ikke-tette indekser for kolonnen(e) filen er fysisk sortert med hensyn på, i vårt eksempel altså PersonNr. Indekser på Etternavn og Adresse vil være tette. Merk imidlertid at for flernivåindekser kan alle indekser bortsett fra det "laveste" nivået være ikke-tette fordi indeksene på "lavere" nivå alltid er sorterte.
En ikke-tett indeks på PersonNr vil inneholde 167 000 innganger. Hver rad i indeksen inneholder 11 byter for å lagre personnummeret og 8 byter for pekeren. Med blokkstørrelse 4KB er det maksimalt plass til 421 indeksrader i hver blokk. Vi antar at hver indeksblokk i gjennomsnitt inneholder 315 rader (som tilsvarer at en blokk er 75% full; valgt ut fra at nodene i et B+-tre alltid inneholder mellom N/2 og N elementer, der N er maksimal "forgreining"). Selve indeksen vil dermed bestå av 530 blokker, så en indeks på nivå 2 vil få plass i 2 blokker. En indeks på nivå 1 vil få plass i en enkelt blokk. Da kan vi lokalisere en person ut fra personnummeret ved 4 diskaksesser (oppslag i de 3 indeksene + 1 oppslag for å finne selve datablokken). Hvis "topp-indeksen" er representert i minnet holder det med 3 diskaksesser.
For Etternavn vil hver rad i indeksen inneholde etternavnet og en peker, la oss si 50 byte. Hver blokk får maksimalt plass til 80 indeksrader. La oss si en blokk i gjennomsnitt inneholder 60 indeksrader (75% full). Ettersom vi må bruke en tett indeks, må vi ha en indeks med 5 millioner rader. Det betyr ca 83 000 blokker. Indeksen på nivå 2 kan være ikke-tett. 83 000 indeksrader får plass i 1383 blokker. Indeksen på nivå 3 får plass i 23 blokker, og indeksen på nivå 4 får plass i 1 blokk. Antall diskaksesser blir dermed 4+1 = 5.
Følgende figur antyder en tett indeks på Etternavn (kun 1 nivå):
Neste figur viser flernivåindeks på Personnummer:
Hashing.
Hashing egner seg godt for direkteoppslag på en bestemt verdi (i hash-nøkkelen). Skal vi finne alle verdier i et intervall er hashing imidlertid til liten hjelp, fordi x<y typisk ikke medfører at h(x)<h(y). Hashing egner seg dermed for den første spørringen, hvis filen er organisert med PersonNr som hash-nøkkel.
Denne oppgaven gikk ut på å prøve ut visualisering av søk og indekser. Her er noen aktuelle nettsteder: